Apache DataFusion Comet#
A high-performance accelerator for Apache Spark
Runs your existing Spark queries on the Apache DataFusion native engine, no code changes required. Also accelerates Parquet scans for Apache Iceberg.
# Add the Comet jar to your existing Spark job — no code changes $ $SPARK_HOME/bin/spark-shell \ --jars comet-spark-spark4.1_2.13-0.16.0.jar \ --conf spark.plugins=org.apache.spark.CometPlugin \ --conf spark.shuffle.manager=org.apache.spark.sql.comet.execution.shuffle.CometShuffleManager // Your existing queries now run on the DataFusion native engine scala> spark.sql("SELECT category, COUNT(*) FROM events GROUP BY category").show() scala> ▍
Off-heap memory and classpath tuning flags are covered in the installation guide.
Run Spark Queries at DataFusion Speeds
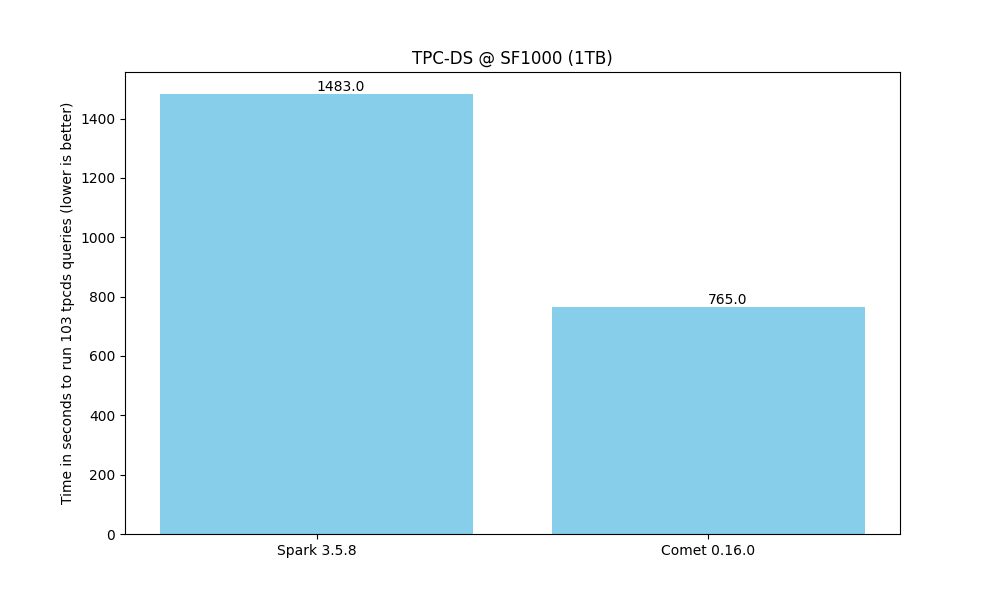
Comet delivers a performance speedup for many queries, enabling faster data processing and shorter time-to-insights.
The chart below shows Comet accelerating TPC-DS @ 1 TB. See the Comet Benchmarking Guide for the full per-query breakdown and reproduction methodology.
Spark Compatibility
100% compatibility with supported Spark versions.
Comet aims for 100% compatibility with all supported versions of Apache Spark, allowing you to integrate Comet into your existing Spark deployments and workflows seamlessly. With no code changes required, you can immediately harness the benefits of Comet's acceleration capabilities without disrupting your Spark applications. The Comet extension automatically detects unsupported features and falls back to the Spark engine.
Use Commodity Hardware
No GPUs. No FPGAs. No vendor lock-in.
Comet leverages commodity hardware, eliminating the need for costly hardware upgrades or specialized hardware accelerators, such as GPUs or FPGA. By maximizing the utilization of commodity hardware, Comet ensures cost-effectiveness and scalability for your Spark deployments.
Architecture
Tight integration with Apache DataFusion.
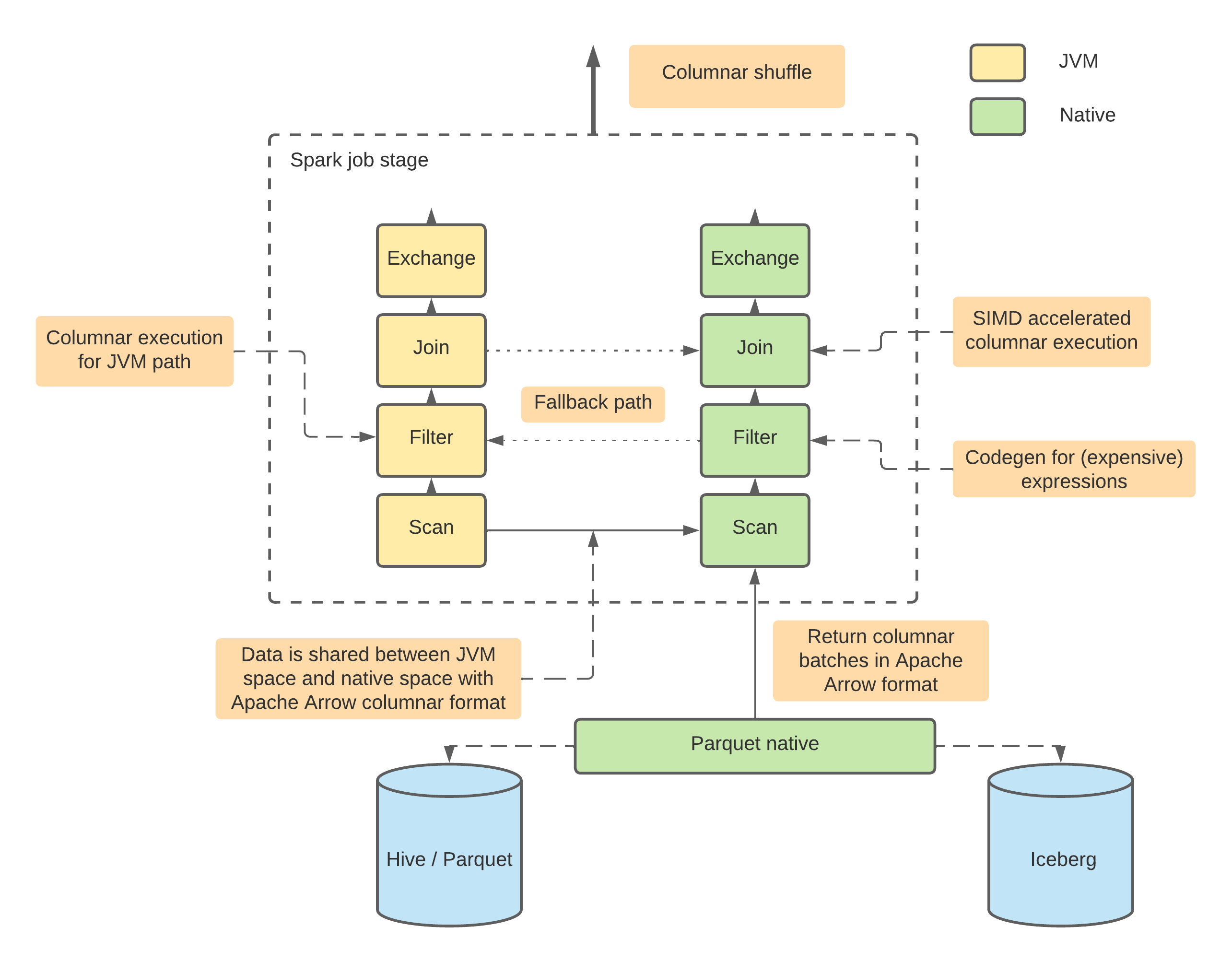
Comet tightly integrates with the core Apache DataFusion project, leveraging its powerful execution engine. The diagram below shows how the Comet plugin intercepts Spark physical plans, translates supported operators into a protocol-buffer representation, and hands them to the Apache DataFusion native engine for execution.
Getting Started
To get started with Apache DataFusion Comet, follow the installation instructions. Join the DataFusion Slack and Discord channels to connect with other users, ask questions, and share your experiences with Comet.
Contributing
We welcome contributions from the community to help improve and enhance Apache DataFusion Comet. Whether it's fixing bugs, adding new features, writing documentation, or optimizing performance, your contributions are invaluable in shaping the future of Comet. Check out our contributor guide to get started.